
[Embeded] Benchmarking Raspberry Pi 2 Hadoop Cluster 논문 정리
요약
이 원고는 설계 및 배포뿐만 아니라 하둡 클러스터의 벤치마크 및 스트레스 테스트에 대한 성능 평가도 포함됨
- 성능
- CPU 900MHz
- 32비트 쿼드 코어 ARM Cortex-A7 CPU 프로세서
- RAM 1GHz 각 노드가 있는 15대의 저가 Raspberry Pi 2 모델 B 컴퓨터
- 이더넷 네트워크 100Mbps
- 스트레스 테스트 도구
- TestDFSIO
소개
하둡(Hadoop) 클러스터 : 오픈 소스 분산 처리 소프트웨어를 실행하고 분산 컴퓨팅 환경에서 방대한 양의 비정형 데이터를 분석하여 데이터 분석 애플리케이션 속도 높임
시스템 설명
- 라즈베리 파이 15대 연결
- 1대 : 마스터 노드
- 14대 : 작업 노드 ( 각각 7개씩 두 그룹으로 스택됨 )
- 구성 요소
- 처리량 100Mbps 16포트 10 / 100Mbps 이더넷 스위치
- 16 or 32 MB microSD 14개
- 마스터 노드에 넣을 32GB microSD
- 320GB 외장 하드 디스크
- 전원 공급용 USB 코드 3개
- 4개 냉각 FAN
- 3개의 전압계
- 150W 3개 스위치 모드 전원 공급 장치
- 5V 출력(전압 강하 조정으로 5.5V 부스트)

- 소프트웨어 도구
- Hadoop 2.7.2
- Hadoop 2.7 버전 이상은 Java 7 이상 필요 ⇒ Java 8 설치
하둡 클러스터 아키텍처
Apache Hadoop 라이브러리는 단일 노드에서 수천 개의 노드로 확장하도록 설계되어 본질적인 이점 때문에 빅 데이터 처리를 위한 산업 프레임워크가 됨
Apache Hadoop은 HDFS(Hadoop Distributed File System)와 YARN 기반의 HadoopMapReduce라는 두가지 핵심 구성요소로 구성됨
하둡 분산 파일 시스템(HDFS)
HDFS는 Google 파일 시스템(GFS)을 기반으로 하며 Java로 작성
응용 프로그램 데이터에 대한 높은 처리량 액세스 제공
대용량 데이터 세트가 있는 응용 프로그램에 적합
마스터와 슬레이브 아키텍쳐로 구성됨
네임노드와 데이터노드는 데이터에 대한 고성능 액세스를 제공하는 분산 파일 시스템 구현함
빠른 데이터 전송을 지원함
파일 및 디렉토리 열기, 닫기, 이름 바꾸기를 포함한 파일 시스템 네임스페이스 작업을 관리하고 클라이언트 응용 프로그램 및 여러 파일에 대한 액세스 제어
HDFS가 데이터 가져올 때 내부적으로 하나 이상의 블록으로 분할
하둡 맵리듀스
일반적으로 많은 양의 데이터를 처리하고 생성하는 프로그래밍 패러다임으로 정의됨
Java로 작성된 소프트웨어 프레임워크 또는 하둡의 데이터 처리 계층, 입력 데이터를 병렬 프로세스에서 실행할 수 있는 더 작은 작업으로 분할하는 기능이 있음
- 분할 단계
- 정렬 단계
- 위상을 줄임
YARN
하둡 클러스터에서 실행되는 다양한 애플리케이션에 시스템 자원을 할당
그래프 처리, 대화형 처리, 일괄 처리 및 HDFS에 저장된 기타 데이터 처리 엔진 지원
용량 스케줄러가 클러스터를 다중 테넌트 시스템으로 실행할 수 있도록 하는 다중 테넌시와 같은 중요한 기능으로 하둡 클러스터 향상시킴
다중 테넌시 아키텍처에서 소프트웨어 애플리케이션의 단일 인스턴스는 각 고객이 테넌트인 여러 고객에게 서비스를 제공함
이 기능을 통해 여러 액세스 엔진이 Hadoop을 공통 표준으로 사용하여 대화형, 실시간 및 동일한 데이터 세트에 동시에 액세스할 수 있음
EX) 멀티 테넌시 아키텍처는 SaaS 공급자의 경우 하나의 데이터베이스 인스턴스에서 애플리케이션의 하나의 인스턴스를 실행하여 여러 고객에게 웹 액세스 제공할 수 있기 때문에 클라우드 컴퓨팅에서 더 넓은 의미를 갖습니다.
설계 및 설정
하둡은 MapReduce 및 HDFS 방법을 사용하여 데이터 저장 및 분산 데이터 처리를 위한 마스터-슬레이브 아키텍쳐를 가지고 있습니다.
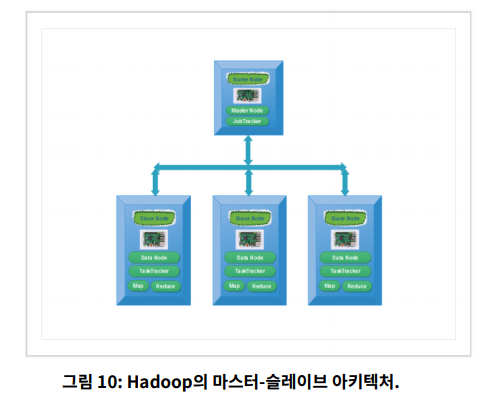
마스터는 Hadoop MapReduce를 사용하여 데이터의 병렬 처리를 수행할 수 있는 클러스터의 노드이며 이름이 지정됩니다.
슬레이브는 HDFS 노드의 상태를 관리하는 데 도움이 되는 노드이며 복잡한 계산을 수행하기 위해 데이터를 저장할 수 있으며 이름이 지정됩니다.
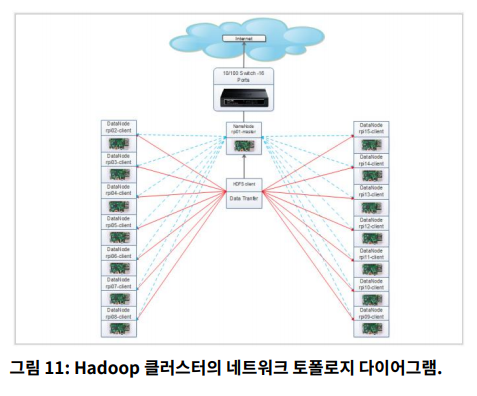
Hadoop 클러스는 16포트 10 / 100Mbps 이더넷 스위치에 연결된 15개의 Raspberry Pi로 구성됩니다.
각 노드는 고정 IP 주소를 가지며 마스터가 보안 쉘을 사용하는 모든 노드와만 통신할 수 있도록 구성됨
참고논문 : https://www.ijcaonline.org/archives/volume178/number42/papakyriakou-2019-ijca-919328.pdf
Leave a comment