
[AI] AICE Associate
AICE Associate
1개의 Tabular Data
파이썬으로 주피터 환경에서 분석 처리 AI 모델링 전과정 14개 문제

Pandas
데이터 프레임 변경, 삭제해보는 것을 추천
데이터 전처리의 주요 기법
- 결측치 처리
- 데이터 타입 변경하기
EDA(탐색적 데이터 분석)
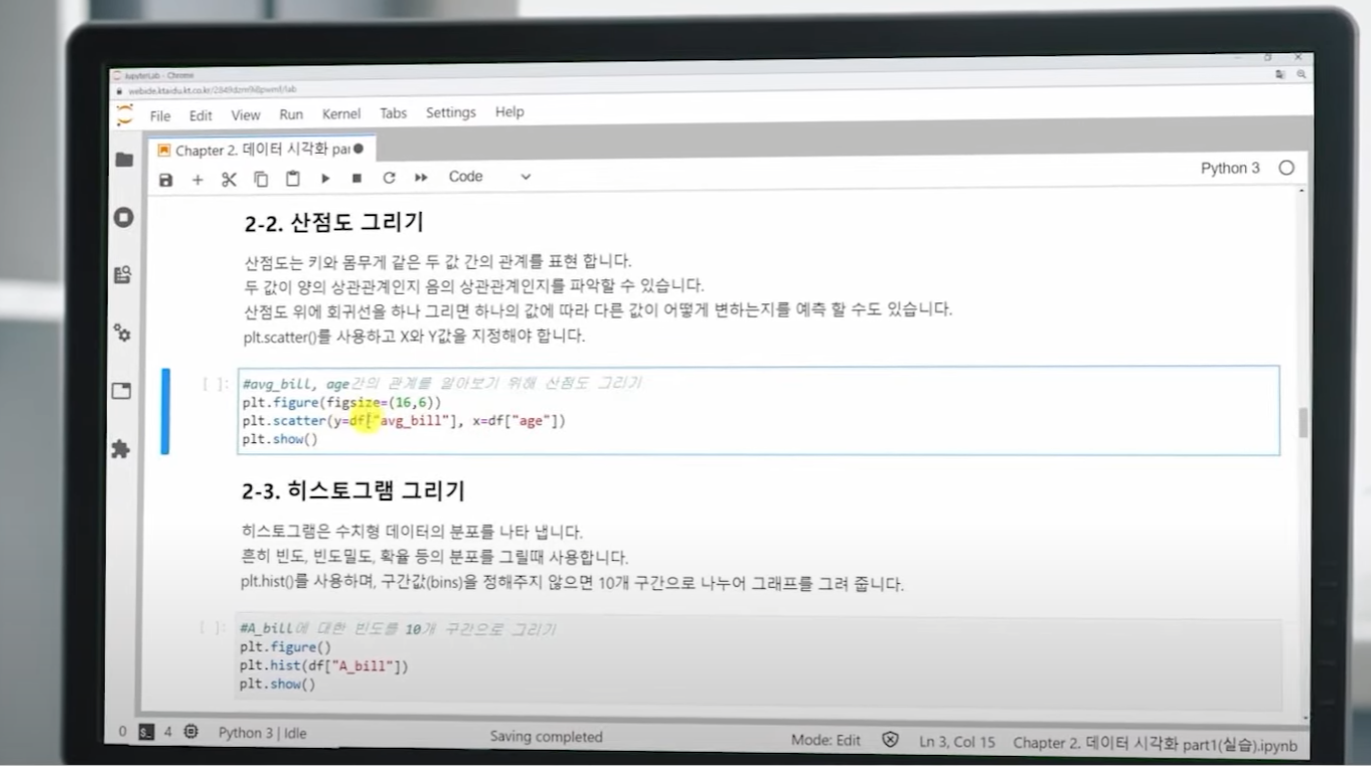
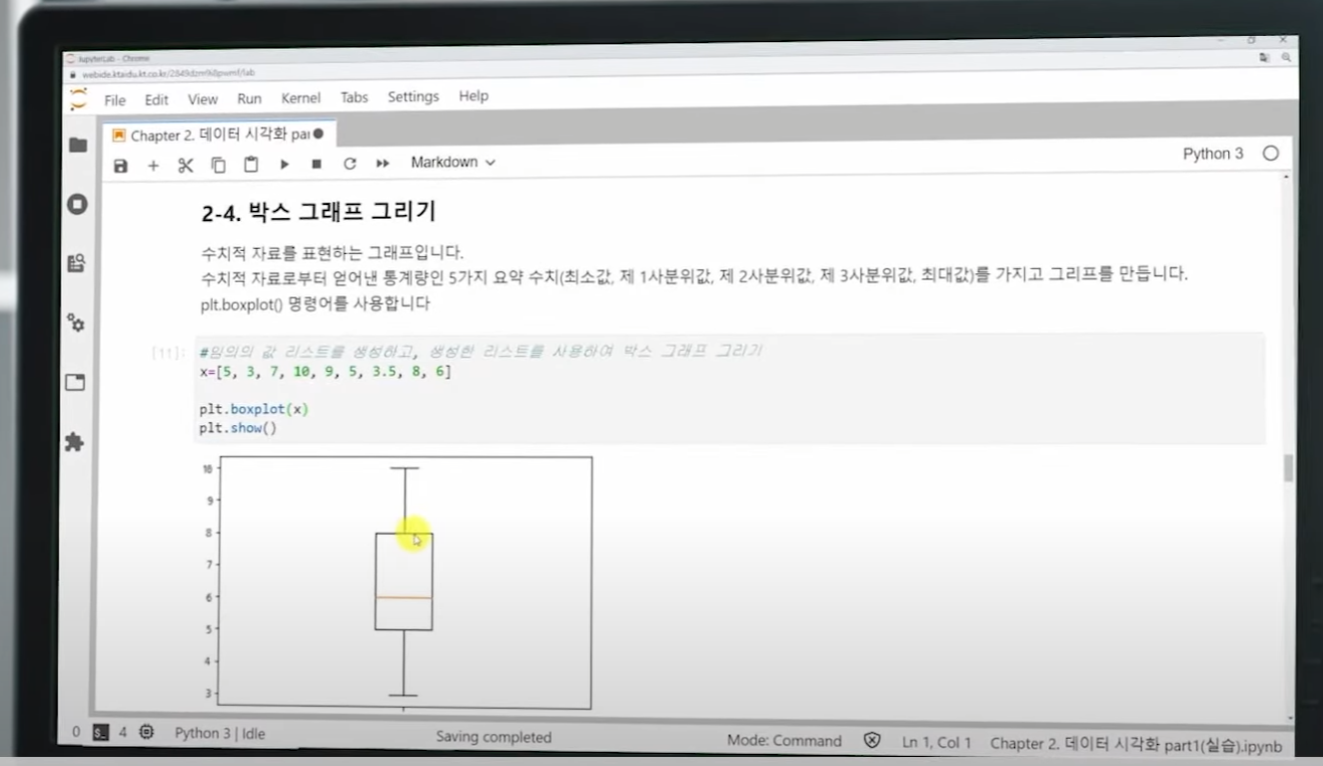
- 시각화 (Matplotlib, seaborn등) : 일반적으로 많이 사용하는 plot을 출력해주는 라이브러리 알아두기
Python
리스트, 딕셔너리, 함수 반드시 이해
시험 문제
단일 모델과 앙상블 복합 모델이 출제 범위
딥러닝 : DNN, FNN 일반 뉴럴 네트워크 다룰 수 있는지
어렵지 않음 코딩 템플릿처럼 다 똑같다
데이터 전처리, 시각화 분야 어려움
AI 개념

인공지능
- 호랑이인지 사자인지 판별
무료 강의 정리
필요 라이브러리 임포트
import numpy as np
import pandas as pd
파일 읽어오기
df = pd.read_csv(’data_v1.csv’)
탐색적 데이터 분석
상위 디폴트 5개 : df.head()
하위 디폴트 5개 : df.tail()
자료구조 파악 : df.info()
데이터 인덱스 : df.index
데이터 컬럼명 : df.columns
데이터 Values : df.values
Null 데이터 확인 : df.isnull().sum()
통계 정보 : df.describe()
데이터 전처리
-
자료 구조 파악 info 사용(Row, column, Not-null, type)
-
customerID는 필요 없으니 삭제
df.drop(’customerID’, axis =1 , inplace=True)
-
범주형 문자 데이터 ⇒ 숫자 변환 필요
-
cond = (df[’TotalCharges’] == ‘ ‘) (df[’TotalCharges’] == ‘’) - df[cond]로 결과 확인 위에 조건이 해당되는 것들이 있다는 거
- df[’TotalCharges’].replace([’ ‘], [’0’], inplace=True)
- df[’TotalCharges’] = df[’TotalCharges’].astype(float)
- df[’Churn’].value_counts()
- df[’Churn’].replace([’Yes’, ’No’], [1, 0], inplace=True)
-
결측치 처리
컬럼별 Null 값 얼마나 있는지 확인 : df.isnull.sum()
- 결측치 처리
- df.drop(’DeviceProtection’, axis=1, inplace=True)
- df.dropna(inplace=True)
시각화
- 라이브러리 import
- import matplotlib.pyplot as plt
- %matplotlib inline
- Bar Chart
- df[’gender’].value_counts().plot(kind=’bar’)
- Object 컬럼 하나씩 가져와서 Bar 차트 그리기
object_list = df.select_dtypes('object').columns.values
for col in object_list:
df[col].value_counts().plot(kind='bar')
plt.title(col)
plt.show()
- Histgram
- import seaborn as sns
- sns.histplot(data=df, x=’tenure’, hue=’Churn’)
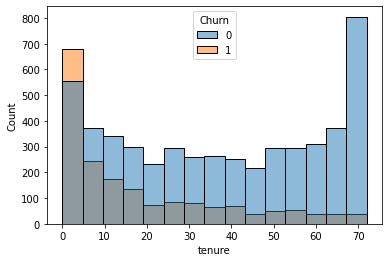
-
곡선 히스토그램 : sns.kdeplot(data=df, x=’tenure’, hue=’Churn’)
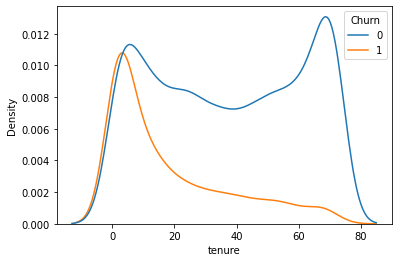
-
Countplot : sns.countplot(data=df, x=’MultipleLines’, hue=’Churn’)
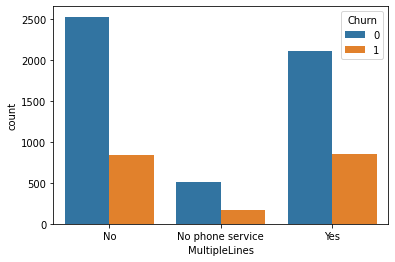
-
heatmap : sns.heatmap(df[[‘tenure’,’MonthlyCharges’,’TotalCharges’]].corr(), annot=True)
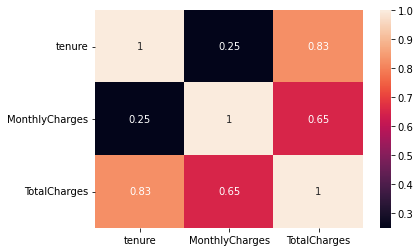
-
boxplot : sns.boxplot(data=df, x=’Churn’, y=’TotalCharges’)
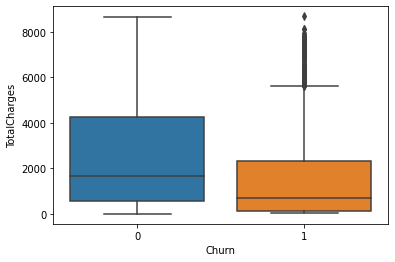
오브젝트 타입 골라서 → 전부 숫자형
- LabelEncoder 활용 : Pandas get_dummies 함수 이용하여 One-Hot-Encoding
cal_cols = df.select_dtypes('object').columns.values
df1 = pd.get_dummies(data=df, columns=cal_cols)
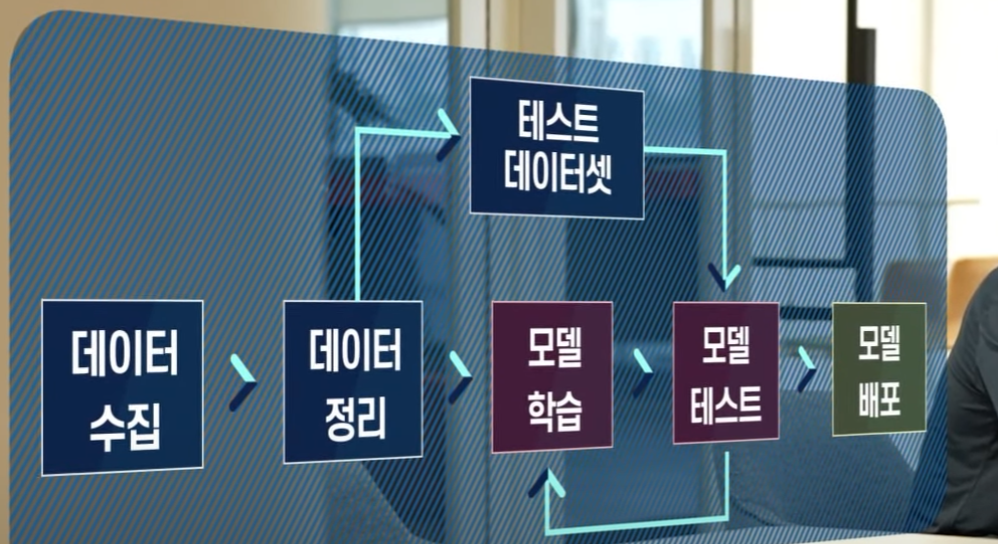
머신 러닝
Tranin, Test 데이터셋 분할
입력(X)과 레이블 (y) 나누기
X = df1.drop('Churn', axis=1).values
y = df1['Churn'].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
데이터 정규화/스케일링(Normalizing/Scaling)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
모델 개발
- 모델별 바차트 그려주고 성능 확인을 위한 함수
# 모델별로 Recall 점수 저장
# 모델 Recall 점수 순서대로 바차트를 그려 모델별로 성능 확인 가능
from sklearn.metrics import accuracy_score
my_predictions = {}
colors = ['r', 'c', 'm', 'y', 'k', 'khaki', 'teal', 'orchid', 'sandybrown',
'greenyellow', 'dodgerblue', 'deepskyblue', 'rosybrown', 'firebrick',
'deeppink', 'crimson', 'salmon', 'darkred', 'olivedrab', 'olive',
'forestgreen', 'royalblue', 'indigo', 'navy', 'mediumpurple', 'chocolate',
'gold', 'darkorange', 'seagreen', 'turquoise', 'steelblue', 'slategray',
'peru', 'midnightblue', 'slateblue', 'dimgray', 'cadetblue', 'tomato'
]
# 모델명, 예측값, 실제값을 주면 위의 plot_predictions 함수 호출하여 Scatter 그래프 그리며
# 모델별 MSE값을 Bar chart로 그려줌
def recall_eval(name_, pred, actual):
global predictions
global colors
plt.figure(figsize=(12, 9))
#acc = accuracy_score(actual, pred)
acc = recall_score(actual, pred)
my_predictions[name_] = acc * 100
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=True)
df = pd.DataFrame(y_value, columns=['model', 'recall'])
print(df)
length = len(df)
plt.figure(figsize=(10, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=15)
bars = ax.barh(np.arange(len(df)), df['recall'])
for i, v in enumerate(df['recall']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=15, fontweight='bold')
plt.title('recall', fontsize=18)
plt.xlim(0, 100)
plt.show()
로지스틱 회귀
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import classification_report
# 로지스틱 회귀로 학습
lg = LogisticRegression()
lg.fit(X_train, y_train)
# 분류기 성능 평가
lg.score(X_test, y_test)
lg_pred = lg.predict(X_test)
# 오차 행렬
# TN FP
# FN TP
confusion_matrix(y_test, lg_pred)
# 정확도
accuracy_score(y_test, lg_pred)
# 정밀도
precision_score(y_test, lg_pred)
# 재현율
recall_score(y_test, lg_pred)
# 정밀도 + 재현율
f1_score(y_test, lg_pred)
# 모델별 바차트
recall_eval('LogisticRegression', lg_pred, y_test)
KNN(K-Nearest Neighbor)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# 모델별 바차트
knn_pred = knn.predict(X_test)
recall_eval('K-Nearest Neighbor', knn_pred, y_test)
결정트리(DecisionTree)
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(max_depth=10, random_state=42)
dt.fit(X_train, y_train)
# 모델별 바차트
dt_pred = dt.predict(X_test)
recall_eval('DecisionTree', dt_pred, y_test)
랜덤포레스트(RandomForest)
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=3, random_state=42)
rfc.fit(X_train, y_train)
# 모델별 바차트
rfc_pred = rfc.predict(X_test)
recall_eval('RandomForest Ensemble', rfc_pred, y_test)
XGBoost
설치 : !pip install xgboost
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimators=3, random_state=42)
xgb.fit(X_train, y_train)
xgb_pred = xgb.predict(X_test)
recall_eval('XGBoost', xgb_pred, y_test)
Light GBM
설치 = !pip install lightgbm
from lightgbm import LGBMClassifier
lgbm = LGBMClassifier(n_estimators=3, random_state=42)
lgbm.fit(X_train, y_train)
lgbm_pred = lgbm.predict(X_test)
recall_eval('LGBM', lgbm_pred, y_test)
딥러닝
라이브러리 import
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
tf.random.set_seed(100)
Sequential 모델 생성
# Sequential() 모델 정의 하고 model로 저장
# input layer는 input_shape=() 옵션을 사용한다.
# 39개 input layer
# unit 4개 hidden layer
# unit 3개 hidden layer
# 1개 output layser : 이진분류
model = Sequential()
model.add(Dense(4, activation='relu', input_shape=(39,)))
model.add(Dense(3, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
과적합 방지 모델 생성
model = Sequential()
model.add(Dense(4, activation='relu', input_shape=(39,)))
model.add(Dropout(0.3))
model.add(Dense(3, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
모델 컴파일
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
모델 학습
# 앞쪽에서 정의된 모델 이름 : model
# Sequential 모델의 fit() 함수 사용
# @인자
### X, y : X_train, y_train
### validation_data=(X_test, y_test)
### epochs 10번
### batch_size 10번
model.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=10,
batch_size=10)
다중 분류 DNN
# 39개 input layer
# unit 5개 hidden layer
# dropout
# unit 4개 hidden layer
# dropout
# 2개 output layser : 다중분류
model = Sequential()
model.add(Dense(5, activation='relu', input_shape=(39,)))
model.add(Dropout(0.3))
model.add(Dense(4, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(2, activation='softmax'))
모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
모델 학습
history = model.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=20,
batch_size=16)
조기 종료 모델
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# val_loss 모니터링해서 성능이 5번 지나도록 좋아지지 않으면 조기 종료
early_stop = EarlyStopping(monitor='val_loss', mode='min',
verbose=1, patience=5)
# val_loss 가장 낮은 값을 가질때마다 모델저장
check_point = ModelCheckpoint('best_model.h5', verbose=1,
monitor='val_loss', mode='min', save_best_only=True)
history = model.fit(x=X_train, y=y_train,
epochs=50 , batch_size=20,
validation_data=(X_test, y_test), verbose=1,
callbacks=[early_stop, check_point])
Oversampling
from imblearn.over_sampling import SMOTE
# SMOTE 함수 정의 및 Oversampling 수행
smote = SMOTE(random_state=0)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train)
# 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_over = scaler.transform(X_train_over)
X_test = scaler.transform(X_test)
# 모델 개발
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(39,)))
model.add(Dropout(0.3))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(16, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 여기서는 val_accuracy 모니터링해서 성능이 좋아지지 않으면 조기 종료 하게 함.
early_stop = EarlyStopping(monitor='val_accuracy', mode='max',
verbose=1, patience=5)
check_point = ModelCheckpoint('best_model.h5', verbose=1,
monitor='val_loss', mode='min',
save_best_only=True)
history = model.fit(x=X_train_over, y=y_train_over,
epochs=50 , batch_size=32,
validation_data=(X_test, y_test), verbose=1,
callbacks=[early_stop, check_point])
Leave a comment